Was ist Data Science?
Data Science ist ein neuer und aufstrebender Forschungsbereich, welcher sich mit der Gewinnung von Wissen und Erkentnissen aus Daten befasst. In einer Ära, in der die Generierung von Daten exponentiell zu nimmt, gewinnt die Disziplin zunehmend an Bedeutung. In diesem Blog-Post werfen wir einen Blick auf die Grundlagen von Data Science, seine Anwendungen und die Fähigkeiten, die ein Data Scientist benötigt.
1. Begriffsdefinition “Data Science” bzw. “Datenwissenschaft”:
Der Begriff kann aus verschiedenen Perspektiven betrachtet werden. Aus übergeordenter Sicht ist: “Data Science die Wissenschaft der Daten” oder “die Erforschung von Daten” oder auch einfach Datenwissenschaft genannt (Cao L., 2017).
Aus fachlicher Sicht ist Data Science ein interdisziplinäres Gebiet, das auf Mathematik und/oder Statistik, Informatik und/oder Informationstechnologien und Domänen- bzw. Fachwissen und/oder Unternehmenskentnissen besteht. In den Schnittmengen dieser einzelnen Disziplinen findet man die traditionelle (wissenschaftliche) Forschung, maschinelles Lernen und Softwareentwicklung (L. Maynard-Atem & B. Ludford, 2020).
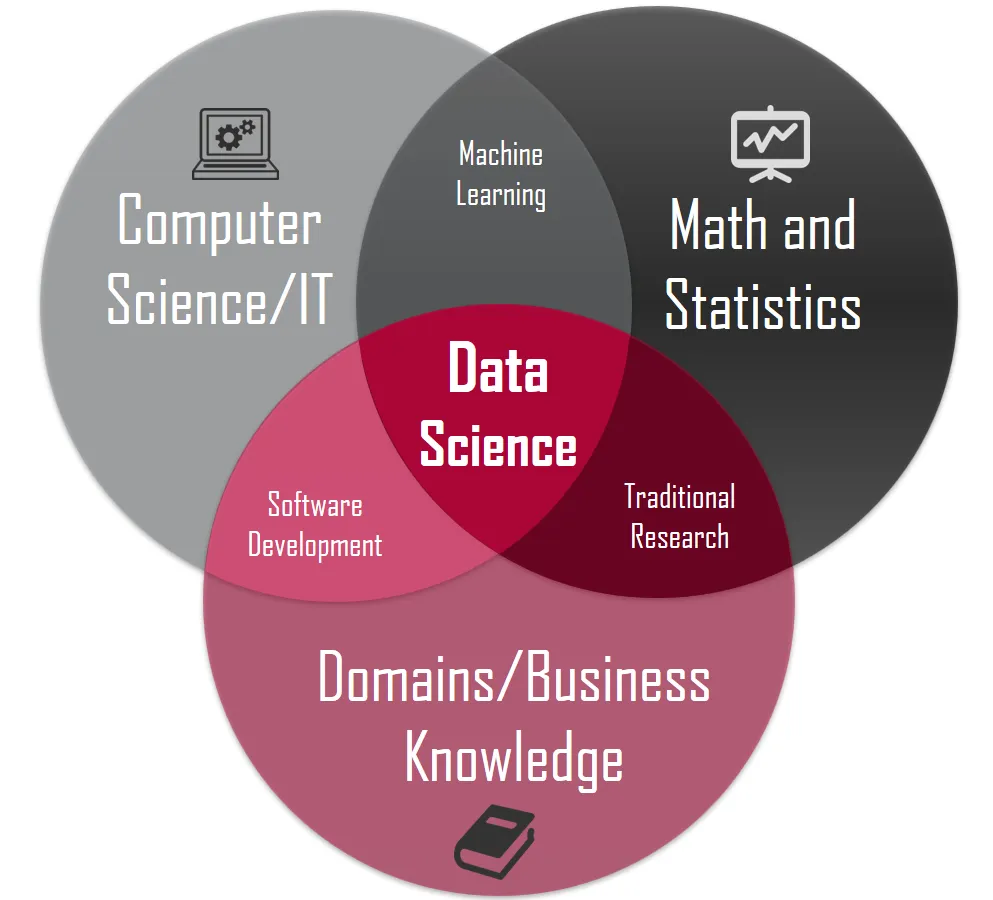
Daneben gibt es auch weitere Defnitionen, welche auch die Bereiche Datenverarbeitung, Kommunikation, Soziologie und Management als erweiterte Bereiche ansehen, da erfolgreiches Data Science durch diese Dimensionen bedingt werden. Ziel ist es, Daten in Erkenntnisse und Entscheidungen zu transformieren, indem man einer Denkweise und Methodik folgt, die von Daten über Wissen zu Weisheit führt.
Aus Prozess-Sicht besteht aus verschiedenen Phasen, die nacheinander durchlaufen werden, um aus Rohdaten wertvolle Erkenntnisse zu gewinnen. Diese Phasen umfassen das Verständnis des Problems, die Datenerfassung, die Datenaufbereitung, die Datenanalyse bzw. Exploration, die Modellierung, die Evaluation und die Kommunikation der Ergebnisse. Jede Phase erfordert spezifische Fähigkeiten und Techniken, um effektive Ergebnisse zu erzielen (C. Nantasenamat, 2020).
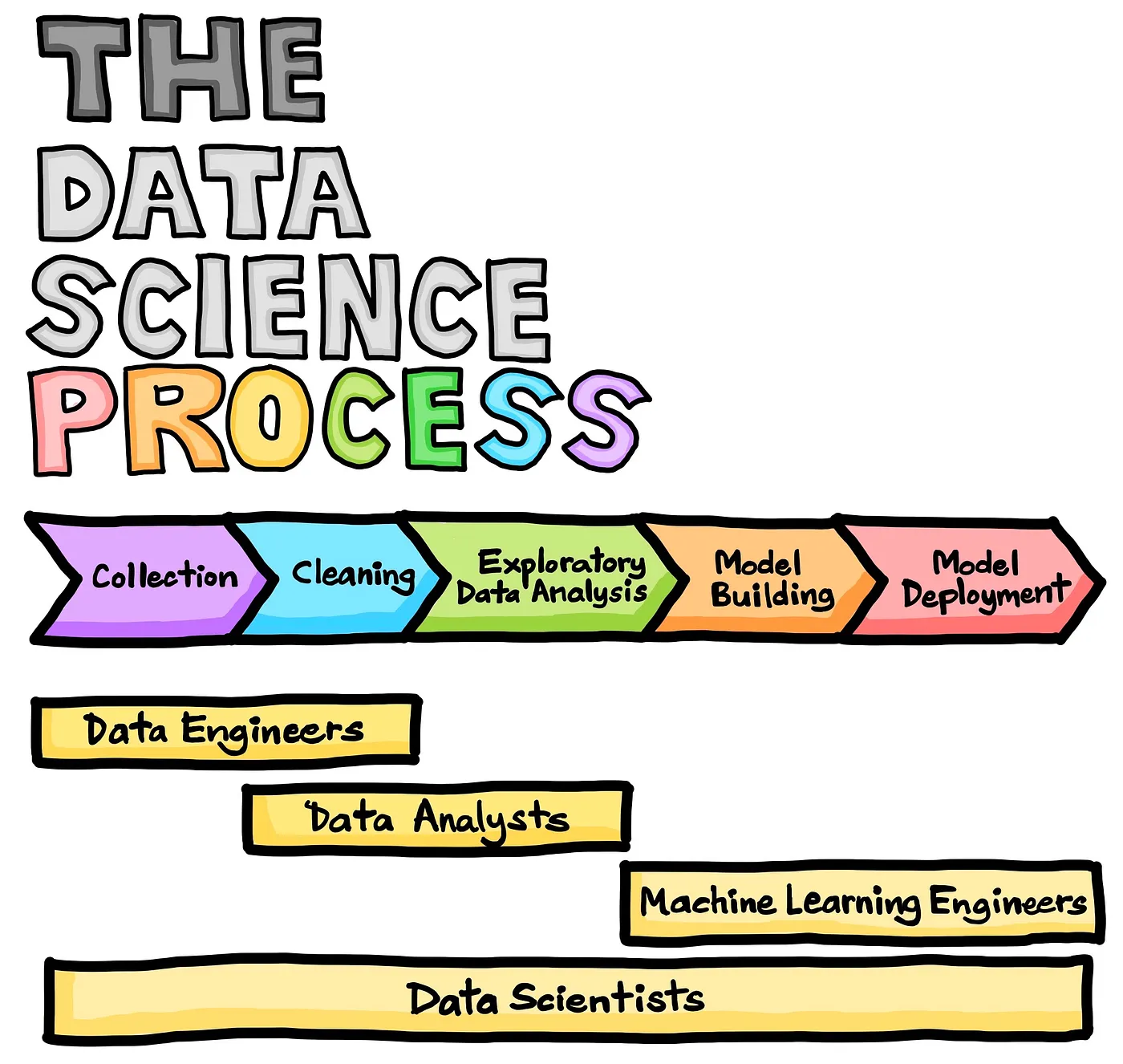
Neben dem Job des Data Scientisten (Datenwissenschaftler), kristallisieren sich hier auch noch andere Job-Rollen wie z.B. Data Engineer, Data Analyst und Machine Learning Engineer heraus, auf welche ich noch in einem anderen Blog Post eingeben werde.
2. Data Mining vs. Data Science:
Data Science ist ein breiteres Feld, das verschiedene Techniken zur Analyse und Interpretation von Daten umfasst, während sich Data Mining speziell auf die Gewinnung von Erkenntnissen aus strukturierten Daten mithilfe statistischer und maschineller Lernalgorithmen konzentriert.
Was macht ein Data Scientist?
Wir geben hier einen Überblick über die neue Job-Rolle, welche Skills benötigt und welche Tools eingesezt werden und warum es der Suche nach einem Einhorn gleicht.
3. Data Scientist: The Sexiest Job of the 21st Century:
Im Oktober 2012 veröffentlichte das Harvard Business Review den Magazin Artikel: “Data Scientist: The Sexiest Job of the 21st Century”, welcher inzwischen auch online verfügbar ist (T. H. Davenport and DJ Patil, 2012). Dieser Artikelt kann durchaus als Meilenstein in der Branche betrachtet werden, da er das neue Jobprofil in das Zentrum der Aufmerksamkeit vieler Unternehmen gerückt hat.
Die Autoren erzählen die Geschichte von Jonathan Goldman, einem Datenwissenschaftler bei LinkedIn, der mithilfe von Datenanalyse und Algorithmen die Funktion “People You May Know” entwickelte, welche das Wachstum von LinkedIn erheblich steigern konnte. Der Artikel erklärt, dass Data Scientisten Entdeckungen in großen Datenmengen machen, Struktur in unstrukturierte Daten bringen und Unternehmen helfen, Daten in wertvolle Erkenntnisse umzuwandeln. Im Aritkel wird betont, dass die Nachfrage nach Data Scientisten das Angebot übersteigt, was zu Engpässen in einigen Brachen führt und Unternehmen große Anstrengungen unternehmen müsse, um Data Scientisten rekrutieren zu können. Die Autoren betonen weitere wichtige Faktoren wie Neugierde, analytischen Fähigkeiten und Kommunikationstalente, um die Ergebnisse auch klar und präzise präsentieren zu können.

Damals wurde auch der Begriff des Data Scientisten als Unicorns geprägt. Es gab 2012 noch keine eigene Ausbildung an Universitäten oder Fachhochschulen, weshalb hoch qualifzierte Data Scientisten Quereinsteiger aus anderen Disziplinen wie Physik, Softwareentwicklung, Mathematik, etc. sehr schwer zu finden waren.
4. Skills von Data Scientisten
Was macht ein Data Scientist? Die erforderlichen Fähigkeiten für Data Scientists können je nach Unternehmen und spezifischer Rolle variieren, allerdings benötigen sie einen guten Mix aus folgenden Hard- und Soft-Skills:
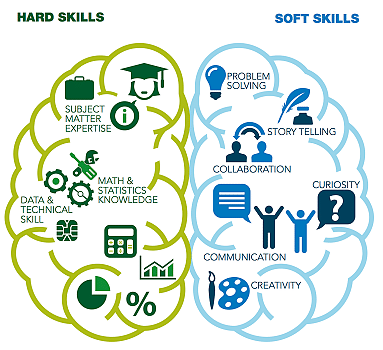
- Programmierkenntnisse: fundierte Kenntnisse in Programmiersprachen sind unerlässlich, um Daten zu manipulieren, Modelle zu entwickeln und Analysen durchzuführen.
- Statistikkenntnisse: Ein solides Verständnis ist unverzichtbar, da statistische Methoden angewendet und Ergebnisse interptretiert werden müssen.
- Kenntnisse im Maschinellen Lernen: verschiedenen maschinellen Lernverfahren wie Supervised, Unsupervised, Deep und Reinforcement Learning als Subdisziplinen der Künstlichen Intelligenz stellen eine Basiskompetenz dar. Sie müssen in der Lage sein, Modelle zu trainieren, zu validieren und zu optimieren.
- Datenbankkenntnisse: sind vor allem im Bereich von Big Data relevant. Kenntnisse über Datenbanken und Datenmanagement zu haben ist also von Vorteil. Das Verständnis von Datenbankabfragesprachen wie SQL und die Arbeit mit Datenbanken wie MySQL gehört zum täglichen Brot.
- Datenvisualisierung: Die Fähigkeit, Daten effektiv zu visualisieren und in aussagekräftige Grafiken oder Dashboards umzuwandeln, ist für die Kommunikation von Ergebnissen und Erkenntnissen entscheidend.
- Datenverarbeitung und -bereinigung: Datenwissenschaftler müssen in der Lage sein, Daten aus verschiedenen Quellen in strukturierter und unstrukturierter Forfm zu sammeln, zu bereinigen und zu transformieren. Die explorative Datenanalyse ist für fast jedes Analytics Projekt Pflicht.
- Problemlösungsfähigkeiten: Datenwissenschaftler müssen über ausgeprägte analytische und kritische Denkfähigkeiten verfügen, um komplexe Datenprobleme zu verstehen und Lösungen zu entwickeln. Kreativität und die Fähigkeit, alternative Ansätze zu finden, sind ebenfalls wertvolle Fähigkeiten.
- Kommunikationsfähigkeiten: Die Fähigkeit, komplexe statistische Konzepte und Analyseergebnisse einem nicht-technischen Publikum verständlich zu erklären, ist entscheidend. Ergebnisse müssen einfach verständlich und klar kommuniziert werden, um Geschäftsentscheidungen auf der Grundlage ihrer Daten zu unterstützen.
- Teamarbeit und Zusammenarbeit: Datenanalysten arbeiten oft in interdisziplinären Teams. Die Fähigkeit, effektiv mit anderen Teammitgliedern, wie z.B. Data Engineers oder Business-Analysten, zusammenzuarbeiten, ist wichtig, um gemeinsame Ziele zu erreichen.
Zu diesem Thema gibt es auch ein hervorragendes kleines Buch, welches ich an dieser Stelle zur Lektüre empfehlen kann (H. D. Harris et. al., 2013).
5. Welche Tools verwenden Data Scientisten?
Wir müssen hier gleich voraus schicken, dass es sich hier um eine Momentaufnahme für 2023 handelt, welche sich auf jeden Fall ändern wird. Wir gehen von der Grundannahme aus, dass die Grundlagen deskriptiver und induktiver Statistik und Wahrscheinlichkeitsrechnung samt Stochastik (“Kunst des Vermutens”) beherrscht werden.
- Excel: Ein sicherer Umgang mit Excel ist wichtig, da man viele Methoden bereits in Excel direkt auf dem eigenen Rechner einsetzen kann.
- SQL: ist die Abkürzung für Structured Query Language, die sich als Standardsprache für die Kommunikation mit zweidimensionalen, relationalen Datenbanken durchgesetzt hat. Mit Hilfe von SQL können Datentabellen erstellt, miteinander verknüpft und editiert werden. Daten liegen oft isoliert in verschiedenen Datenbanken, weshalb diese Sprache noch immer ein wichtiges Fundament darstellt, um Daten aus IT-Systemen zu extrahieren.
- Python: wurde von Guido van Rossum entwicklet und wird noch immer als die erste und wichtigste Programmiersprache betrachtet, welche Datenwissenschaftler lernen sollten. Als ich noch BWL studiert habe, war SPSS das wichtigste Tool für Statistiker, was sich aber rapide über die Jahre geändert hat. Python ist wie R open-source und kann mit Admin Rechten auf dem eigenen Computer, einem Server oder in der Cloud installiert werden.
- R: wurde von Ross Ihaka and Robert Gentleman an der Universität von Auckland zur Lehre entwicklet. R ist die zweitpopulärste Programmiersprache und wird vor allem im sozial- und wirtschaftswissenschaftlichen Kontext eingesetzt.
- Datenvisualisierung: Nach der Extraktion von Datensätzen aus verschiedenen Datenquellen und Aufbereitung der Daten, können die Ergebnisse schon sehr gut innerhalb mit Zusatzpakten wie z.B. ggplot2 oder matplotlibvisualisiert werden. Darüber hinaus gibt es noch interessante Projekte wie Shiny, Bokeh oder im JavaScript Bereich D3.js. Daneben sind natürlich auch noch die kommerziellen Lösungen von Tableau und Power-BI zu erwähnen, wobei es für Windows User für Power-BI eine Gratis Desktop Version gibt. Bei der Umsetzung von Data Science Projekten geht es schließlich auch darum das Wissen aus den Daten für jede Person im Unternehmen verständlich zu visualisieren.
Einige Tools benötigen Admin Rechte auf dem eigenen Rechner und die Datenpakete benötigen eine offene Internetverbindung nach außen. Selbstverständlich kann das gesamte Setup auch direkt in der Cloud gehostet werden.
Folgende Visualisierung zeigt beeindruckend wie rasch sich die Systemlandschaft über die Jahre verändert hat und weiter verändert.
6. Wieso Data Science? Anwendungsbereiche in Unternehmen:
Data Science kann in jedem Unternehmen in jeder Größe und Branche angwendet werden, solange die Geschäftsführung sich der Wichtigkeit von datengetriebenen Entscheidungsfindungen überzeugt ist und daraus konkrete Handlungsempfehlungen ableitet. Viele Unternehmen tun sich allerdings schwer erste Anwednungsfälle zu definieren, weshalb ich hier ein paar Beispiele aus meiner bisherigen Analytics Projekte nennen möchte:
- Predictive Analytics: Data Science wird oft eingesetzt, um Vorhersagemodelle zu entwickeln, die Unternehmen dabei unterstützen, zukünftige Ereignisse, Trends oder Verhaltensmuster vorherzusagen. Dies kann beispielsweise in den Bereichen Kundenverhalten, Absatzprognosen, Risikomanagement oder Prognose des Lagerstands genutzt werden.
- Personalisierung und Empfehlungssysteme: Data Science ermöglicht es Unternehmen, personalisierte Produkte, Dienstleistungen oder Empfehlungen anzubieten. Durch die Analyse von Kundendaten können Unternehmen individuelle Präferenzen, Bedürfnisse und Verhaltensmuster erkennen und darauf basierend maßgeschneiderte Angebote erstellen um das Kaufverhalten zu optimieren.
- Optimierung von Geschäftsprozessen: Data Science kann eingesetzt werden, um Geschäftsprozesse zu optimieren und Effizienzsteigerungen zu erzielen. Dies umfasst beispielsweise die Analyse von Logistikdaten, um die Lieferketteneffizienz zu verbessern, oder die Anwendung von Prognosemodellen, um die Produktionsplanung und Lagerbestände zu optimieren.
- Kundenservice und Sentiment-Analyse: Data Science ermöglicht es Unternehmen, Kundenservice und -erfahrung zu verbessern. Durch die Analyse von Kundendaten, Social-Media-Interaktionen und Feedback können Unternehmen Einblicke in die Zufriedenheit der Kunden gewinnen und frühzeitig auf Probleme reagieren. Sentiment-Analyse kann dabei helfen, Meinungen und Stimmungen der Kunden zu verstehen.
- Risikomanagement und Betrugserkennung: Data Science spielt eine wichtige Rolle im Risikomanagement, insbesondere in Bereichen wie Versicherungen und Finanzdienstleistungen. Durch die Analyse großer Datenmengen können Risikomodelle entwickelt werden, um potenzielle Risiken zu identifizieren und Maßnahmen zur Risikominderung zu ergreifen. Ebenso können Betrugserkennungssysteme auf der Grundlage von Data-Science-Techniken verdächtige Muster und Anomalien in Transaktionsdaten erkennen.
- Bildanalyse: ein weiterer bedeutender Anwendungsbereich der Data Science, der Unternehmen wertvolle Einblicke und Erkenntnisse bietet. Mit fortschreitenden Technologien zur Bilderkennung und maschinellen Lernverfahren können Unternehmen große Mengen visueller Daten analysieren und aus ihnen wertvolle Informationen gewinnen. Durch die Anwendung von Algorithmen zur Bilderkennung und -segmentierung können Objekte, Muster und Merkmale in Bildern automatisch identifiziert und klassifiziert werden. Dies ermöglicht Unternehmen beispielsweise die automatisierte Überwachung von Produktionsprozessen, die Erkennung von Defekten oder Anomalien in visuellen Inspektionen, die Verarbeitung von medizinischen Bildern für Diagnosen oder die Analyse von Bildern in der Sicherheitsüberwachung. Die Bildanalyse eröffnet Unternehmen somit vielfältige Möglichkeiten zur Optimierung von Prozessen, Verbesserung der Qualitätssicherung und Entwicklung neuer datenbasierter Produkte oder Dienstleistungen.
Letztlich geht es darum Wissen aus Unternehmensaten zu generieren, welchen einen direkten Mehrwert für das Unternehmen darstellen und als Grundlage zur Entscheidungsfindung dienen.
6. Data Science in Tirol
In Tirol gibt es inzwischen mehrere Studiengänge und Zusatzausbildungen, welche ich in einem separaten Blog Artikel erklären werde. Von der Standortagentur Tirol wird seit kurzem ein eigener Stammtisch organisiert, welcher bereits 2 Mal statt gefunden hat. Daneben organisiert Fraunhofer Österreich die sogenannten IZT Expert Talks, welche regelmäßig in Wattens statt finden. Gerne können Sie sich natürlich auch mit mir auf einen unverbindliches Gespräch treffen.
7. Weblinks
Papers & Articles:
- Cao, L. (2017). Data Science. ACM Computing Surveys, [online] 50(3), pp.1–42. doi: https://doi.org/10.1145/3076253.
- Maynard-Atem, L. and Ludford, B. (2020). The Rise Of The Data Translator. Impact, 2020(1), pp.12–14. doi:https://doi.org/10.1080/2058802x.2020.1735794.
- Nantasenamat, C. (2020). The Data Science Process. [online] Medium. Available at: https://towardsdatascience.com/the-data-science-process-a19eb7ebc41b.
- Davenport, T.H. and Patil, D.J. (2017). Data Scientist: The Sexiest Job of the 21st Century. [online] Harvard Business Review. Available at: https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century.
-
Inc.Outlook (2019). What all you need to know about statistics for Data science? [online] Medium. Available at: https://medium.com/@incoutlook1/what-all-you-need-to-know-about-statistics-for-data-science-f87edbc742d8 [Accessed 30 Jun. 2023].
Bücher:
- Harris, H., Vaisman, M. and Murphy, S.P. eds., (2013). Analyzing the Analyzers. [online] www.oreilly.com. Available at: https://www.oreilly.com/library/view/analyzing-the-analyzers/9781449368388/.
Tools:
- Python
- R
- matplotlib (Py)
- ggplot2 (R)
- Shiny (Py und R)
- Bokeh (Py)
- D3.js
- Tableau
- Power-BI
- Power-BI Gratis Desktop Version für Windows